A safer kind of AI for when conversation matters most.
AdviceBuddy is a 24/7 AI companion for mental wellness — engineered for empathy, monitored for safety, and architected so that highly sensitive conversations never leave a controlled environment.
Client
Confidential · US
Industry
HealthTech · Mental Wellness
Region
United States
Status
Live in Production
1–2s
Warm Chat Latency
<500ms
Core API Response
5
Subscription Tiers
24/7
Crisis-Safe Coverage
/ The Challenge
Mental health AI is the most demanding kind of AI you can ship.
A general-purpose chatbot can ship rough edges. A mental wellness companion cannot. Every layer — model, infrastructure, data, billing — has to be safer-by-default than the industry norm.
/ 01 · Safety
Empathetic, but never reckless
The AI had to be conversational and warm — and immediately step aside when a user expresses crisis, surfacing official hotlines instead of generated text.
/ 02 · Privacy
Sensitive data needs sovereignty
We couldn't route deeply personal conversations through general-purpose public LLM APIs. Inference had to happen on infrastructure we controlled.
/ 03 · Monetization
Five tiers, dynamic limits
Free, Basic, Pro, Pro Plus, and Premium — each with its own message budgets, model access, and rate-limit ceilings, all enforced server-side without leaks.
/ 04 · Reliability
Low latency, every conversation
An empathy product cannot stall. Cold-starts, queue depth, and inference cost all had to be solved on a shoestring without compromising the experience.
/ The Solution
A self-hosted LLM stack with safety wired into every layer.
We deployed Llama 3.1-8B-Instruct on serverless GPUs, paired it with a deterministic safety layer, and gave the platform a serverless backend that stays cheap until traffic genuinely demands more.
Real-time typing indicators and a soothing visual system tuned for users in distress
LocalStorage chat persistence — keeping PHI off the central database where possible
/ AI & Backend
Self-Hosted & Private
Llama 3.1-8B-Instruct deployed on Modal serverless A10G GPUs
Supabase Postgres with Row Level Security & service-role isolation
Stripe webhooks + tiered subscription engine
Zod validation & truncation across every entry point
/ Safety Layer
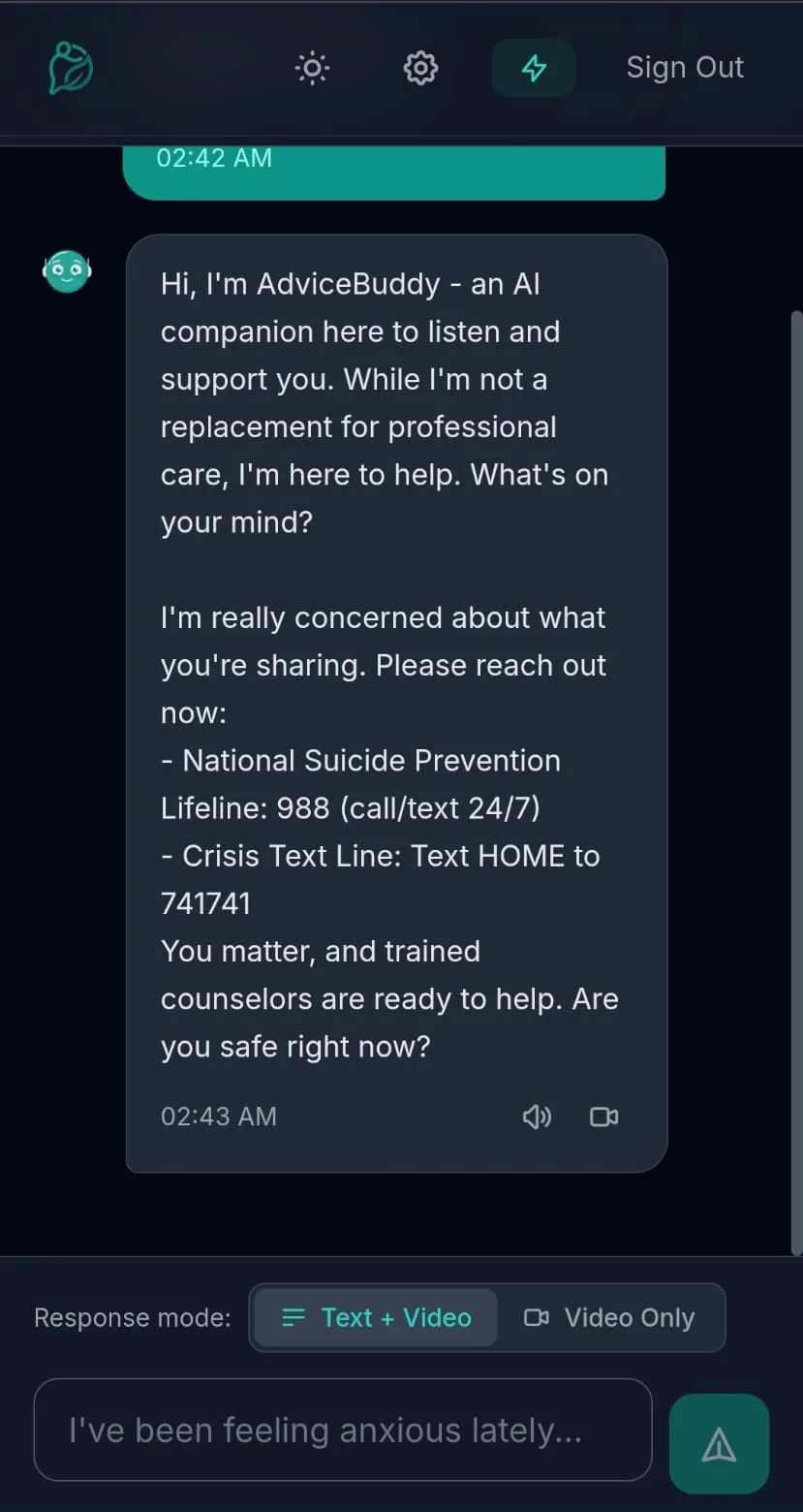
Crisis detection that overrides the model.
When a user expresses severe distress, the system halts the AI and surfaces human-verified resources before any generated response can reach them.
How have you been feeling these last few days?
Honestly, a bit overwhelmed. I don't know what to do.
That sounds heavy. Let's break it down together — what's been weighing on you most?
⚑ Crisis Override · Resources surfaced 988 Suicide & Crisis Lifeline · Crisis Text Line "HOME" → 741741
Keyword + Heuristic Detection
A deterministic safety net that runs before model inference and instantly hands off to verified crisis resources — no chance of a generated response in those moments.
RLS & Service-Role Isolation
Row Level Security at the Postgres layer means users can strictly only read their own data. Backend service-role operations are sealed off from the client SDK.
Validated & Truncated I/O
Every message is Zod-validated and length-capped before inference, preventing injection, buffer attacks, and runaway context windows.
/ Monetization
Five tiers, enforced at the database — not the UI.
Stripe handles billing; Supabase enforces the limits. Every plan upgrade or cancellation flows through a webhook into a single source of truth that the API consults on every request.